April 7, 2026
Following the Agentic Search Debate

By now we’ve all learned that an agent is only as good as its context. Since the word “agent” first appeared we’ve seen a few trends for knowledge retrieval: in-context learning, tool use, RAG etc. The pendulum seems to swing between deep, often graph-like systems with robust search capabilities on one side and flat context lakes with a set of simple but composable commands on the other.
In this post we’ll review a cluster of recent articles that explore the same question: what retrieval interface should agents use to search for context? Let’s see how AI vendors and search engine developers approach this problem from different sides and what principles they use in designing their retrieval toolsets.
The Debate So Far
Filesystems as Interface
Mintlify is a company that helps create and maintain documentation. Their agents need an ability to search customers’ documents efficiently and quickly, while respecting access rules. They’ve recently posted an article describing how they approach this problem. They started by spinning up a sandbox for every agent where it could download and analyze documents. However that resulted in the unacceptable 45 second spin-up time for a session. They needed some way to let the agent use familiar tools, while reducing resource usage and startup time. The core of their solution is ChromaFS, a virtual filesystem that lets agents use grep, cat, ls, find over documentation stored in Chroma. They still use Chroma based search to produce a coarse list of candidates, then the system uses grep to perform the fine search. This way they don’t replace RAG completely, but rather use a filesystem and simple shell commands as retrieval interface.
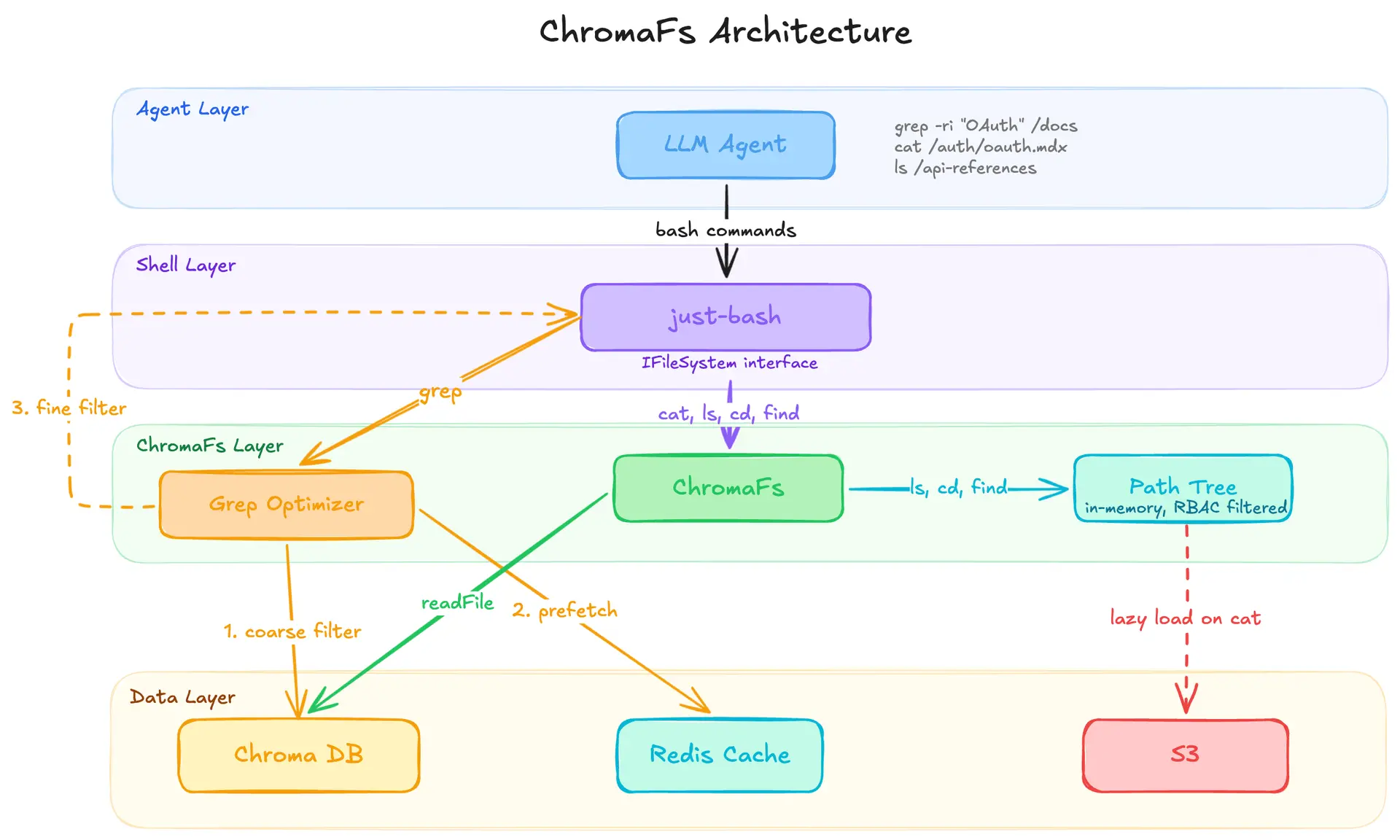 ChromaFS architecture. (C) Mintlify, 2026
ChromaFS architecture. (C) Mintlify, 2026
It’s interesting to note that Claude Code followed a similar trajectory to the limit. Their search evolved from RAG over vector database to grep and then to progressive disclosure via skills. They note that the RAG approach was “powerful but fragile, required indexing, and the model was given context instead of finding it itself.” Now Claude uses fewer simpler commands to search and build context on its own.
Smart Harness Over Dumb Tools
Search specialist Doug Turnbull responded directly to Mintlify’s article. He agrees agents can work well with “dumb retrieval tools”, not just because grep is prevalent in training data, but because constraints force better search behavior. His key point is that harness design matters more than tool choice. His post outlines a basic structure of a harness that gives agents enough constraints and feedback to let them built the right context:
- Inner loop: agent iterates with common tools until it is satisfied with the result.
- Outer loop: hooks validate results until our guardrail conditions are met (recency, authority, relevance etc.)
Having described this idea, Doug then notes that this approach is still suboptimal for context retrieval. Not only the token cost grows with every tool use, but so does execution time. By contrast, modern search engines already provide the ability to rank results by multiple relevance factors.
Designing the Tool Interface
Speaking of modern search engines, Elastic summarized the practices from their internal teams that build database retrieval tools.
Their key finding is that the tool interface itself is where most retrieval quality comes from. That includes descriptions, parameters, output format, but most importantly the right choice of tools themselves. Core principle: “low floor, high ceiling”:
- Low floor represents specialized tools that wrap pre-built queries. That doesn’t leave much freedom to the agent, but ensures low latency, low cost and high retrieval quality. For example,
find_similar_resolved_tickets(problem_description) - High ceiling, that’s the general purpose tools. They are simple in implementation, but the agent has to write the SQL/ESQL query from scratch. Higher flexibility in this case is balanced by higher reasoning overhead and chance of error.
The point is that both types are needed. Specialized pre-built queries handle the most popular, repeating queries, while general-purpose commands are the safety net for rare outlier cases.
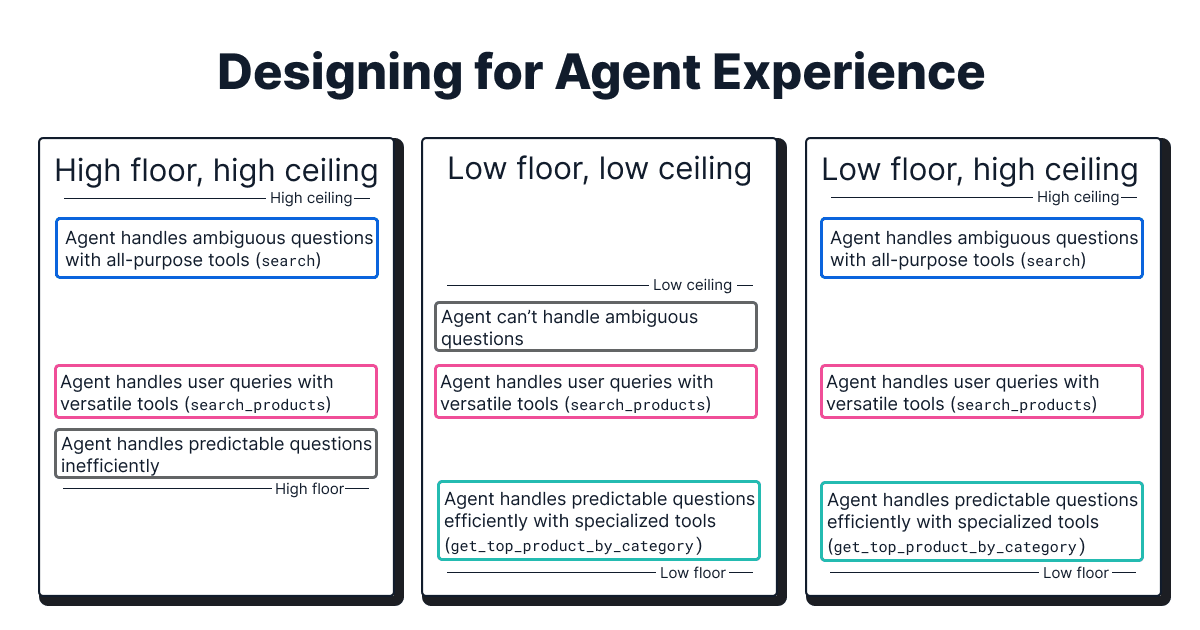 Low floor and high ceiling. (C) Elastic, 2026
Low floor and high ceiling. (C) Elastic, 2026
Another guiding principle is avoiding atomic tools. Elastic initially exposed many small tools (get_index_mappings, generate_esql, execute_query), but that just confused the agents and filled context with intermediate results. The better practice here is to wrap multiple atomic tools into a self-contained search tool. Even if the use cases are different, this still resembles Claude Code’s evolution from many small tools to fewer, more capable ones.
Let the Model Shine
In their recent guide for Claude users Anthropic recommends progressively removing harness scaffolding as models improve. As they put it, with rapidly developing model capabilities the question should always be “what can I stop doing” to let Claude manage its own context.
On the other side, Sebastian Raschka in his excellent overview of coding agent components describes the six building blocks of coding agent harnesses and concludes that the harness shapes most of the user experience. Specifically context management is often what drives quality more than the choice of the model. Elastic’s experience sort of confirms that: teams that don’t limit search results or curate fields in returned documents saw agents get lost in the ballooned up context.
It looks like Anthropic and Raschka both agree that proper context management is key, but they differ on who should take the lead: model or harness.
Common Ground
We can extract some common principles from these sources:
- Agents should build their own context. Modern models have the capability to select relevant knowledge, whether via
grep, filesystem navigation or tool calls. - Harness matters as much as the model. Toolset, context management and validation loops influence quality more than model choice alone.
- Progressive disclosure beats greedy loading. Agents tend to get lost when context windows are full with descriptions of all possible tools. They perform better when they can discover relevant knowledge through layers of increasing detail. See also my previous post expanding on this topic.
- Constraints improve output. The more structure you can put into tool signatures, validation hooks and limited action spaces, the better for agent efficiency. Elastic’s “low floor” tools are essentially constraints: they reduce reasoning overhead and increase first-run success.
- Tool response size must be actively managed. Uncontrolled tool output is likely to become the primary bottleneck on quality. Refer to Elastic’s length/width/depth framework outlined in their article for some ideas on cutting irrelevant detail.
- Atomic tools cannot replace self-contained ones. Both Elastic and Claude Code evolved away from many atomic tools toward fewer, more capable ones. Intermediate results that agent receives from tool calls tend to waste context space and confuse tool ordering.
Of course, all these sources also have points where they disagree, both because they optimize for different use cases, and because the context management field is now in the period of active development. The question of whether grep can replace ranked search really has different answers, depending on the use case and the nature of your knowledge base.
I strongly recommend reading every article I’ve linked in this short overview. They are all illuminating in their own way, and show the diversity of approaches that make information retrieval such a fascinating subject these days.
References
- How We Built a Virtual Filesystem for Our Assistant — Mintlify
- Claude Code’s search evolution — trq212 on X
- Agentic Search Is Having a Grep Moment — Doug Turnbull
- Database Retrieval Tools for Context Engineering — Elastic
- Harnessing Claude’s Intelligence — Anthropic
- Components of a Coding Agent — Sebastian Raschka
- Baking the Context Cake — The Elder Scripts
If you have some thoughts you'd like to share, please reach out to theelderscripts@gmail.com. I read every email!
Yury
Engineering manager and data engineer. Writing about software engineering, data, AI, and team leadership.
@Heliocene